我的競爭優勢? 視覺化口碑定位雷達圖輕鬆搜出來!(附實現程式碼)
企業競爭者的調查方式 vs 網路特性
企業的品牌以及形象,是企業一向非常重要的無形資產,沒有一個企業會忽視他的重要性,尤其會與其競爭者相互比較,知道自己在市場上的位置。一般調查的方式,都以問卷的方式居多,但由於社會形態的改變,用問卷調查競爭者的方式,漸漸產生了幾個缺點:
- 隱私權的興起,問卷填寫率越來越難掌控
- 網路問卷填寫者大多因為獎品而隨意亂填
- 填寫問卷時,因題目而有所侷限,所以無法充分顯示非結構化文字的意涵
- 每做一次問卷,必須要花費不少成本
- …
諸如此類的問題,嚴重影響了結果的準確性。讀者可發現問卷在動態競爭的環境中較不易發揮即時快速的特性,更遑論網路輿情言論滿天飛的21世紀。
(但這並不代表問卷一無是處,在調查特定特徵市場區隔變數時或特定問題時,是有可用之處的,詳情可以參考行銷研究、資料庫行銷與行銷資料科學之比較-1)
反觀網路世界,大多數的人都將想法以及討論,放到網路上了,因為網路有匿名的特性,每個人可以不受心理壓力的狀況下,忠實的表達心中的想法, 而這網路輿情,對企業便是把雙面刃。好的行銷手法,可造就大量的銷售業績,但一旦有流言蜚語,便可能壞事傳千里。

網路輿情如同雙面刃,好事、壞事傳得快,但相對的,企業也能更快速使用行銷資料科學技法,取得快速的網路輿情資訊
如何及時觀察網路輿情「雙面刃」?
本文將帶領讀者,透過網路輿情分析,找到自己品牌在網路上的「定位」。這時,我們可簡單透過「定位圖」的概念,抵禦雙面刃帶給我們的外部效益與成本。
實務上,企業在繪製定位圖時,「屬性的確認」與「屬性的衡量」是最大的挑戰。好的屬性有機會協助企業找到新的定位。而屬性的衡量,一般是透過行銷研究或內外部資料分析的方式來進行,例如︰透過問卷調查的方式來收集消費者的資料,進而找出重要特性。只是,問卷調查工具有其限制,成本、時效、樣本接觸…等,都是可能的限制。
當行銷資料科學出現後,除了傳統的行銷研究工具,行銷人員還多了行銷資料科學工具可以使用。我們可以透過網路爬文工具,將消費者在網路上談論公司產品(品牌)、競爭者產品(品牌)的文章進行擷取。再透過分析工具,對這些文章進行分析, 了解該目標市場討論的屬性為何?重視的屬性為何?並且在這些屬性上,顧客對各競爭者屬性的知覺狀況。
透過資料科學工具,我們可以彌補以下幾項實務定位上常見的缺失:
- 定位衝突:所欲達成的定位,出現相互衝突的訴求。例如:一家餐廳強調其擁有最好的食材、最好的服務、最低的價錢…,這些訴求本身相互衝突。便可透過消費者的輿情,了解我們跟其他餐廳定位到底差在哪裡。
- 認知不一致:公司的主管與員工對品牌定位的認知不同。透過消費者的輿情,由第三方認知客觀判斷公司所處定位。
- 混淆定位、區隔與廣告:分不清定位、區隔與廣告之間的關係,或是認為廣告訴求就是定位本身,訴求並不是公司說的算,要消費者說了算,廣告訴求打得再多,還是要看消費者心中相較於其他品牌來說,該訴求是否是消費者真正購買的因素。所以這時便要了解公司訴求相較於市場同業來說,是否真的被消費者所青睞。
實作開始! 視覺化口碑定位雷達圖
以下面的例子進行說明,我們以汽車品牌在網路論壇(PTT)上的網友討論,來做分析。
首先先將論壇汽車版上的所有資料都爬下來,當然包含文章內容,網友評論等,都是真實爬下來子資訊,但由於保護品牌,將品牌名稱做了代號處理,以下會以A、B、C、D、E、F、G、H,分別代表八個不同的汽車品牌。
品牌在PTT中的文章數量比較圖
首先,下圖是「品牌在PTT中的文章數量比較圖」,Y軸是文章聲量,X軸是各品牌名稱。我們可以看到B這個牌子在論壇中的文章數量是很高的,但這並不能代表他們的產品很棒,只能顯示這個品牌的聲量相較其他品牌來說,是非常高的。
所以這樣產品這樣倍受青睞,相信銷售業績也不錯吧! 恩!? 真的嗎?
但請注意,這個論壇的使用者年齡層大約在15~30歲上下,因此並不能代表整個的消費市場,等到這群人成長至購買能力強的中年,如還是呈現這樣的趨勢,便能代表整個市場的購買主力很有可能就在B牌中。雖然這群顧客僅是15~30歲的年輕人, 但這不代表這群年輕人不重要,因為每一家企業的顧客都會老,因此任何一個企業除了要留住老顧客,更要對年輕人訴說你的品牌,漸漸使年輕人成為支撐您公司最重要的支柱。
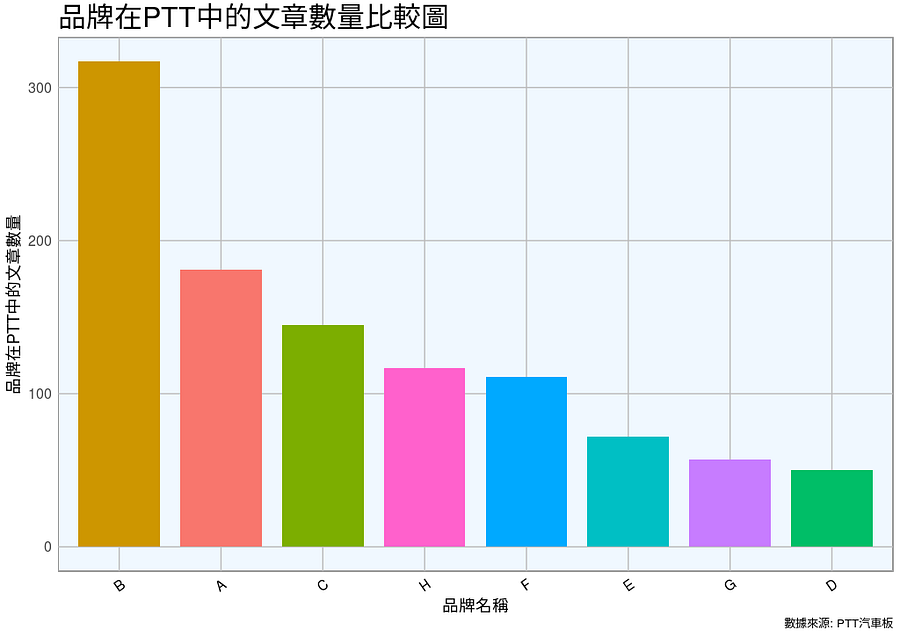
雖然以年輕族群來說,B牌的汽車可能不如預想的賺到大把鈔票但B牌等於在培養「下一代消費力強的顧客」
難道聲量代表一切嗎? 難道沒有其他特別應注意的嗎?! 當然有!讓我們來看看簡易的「情緒評價分析」部分吧!
品牌的正評/負評數量比較百分比
下圖是「品牌的正評/負評數量比較百分比」,Y軸為正負評價比例,如果藍色>0.5 ,代表有一半以上正評價多於負評價,反之,則是負面評價大於正面評價;X軸則是各品牌名稱。
為了要得知正負評價分析的結果,我們在此細分每一個評論,將每一個網友的留言分段後進行字詞的情緒評價分析,得到以下的結果,很明顯的可以看到,雖然B牌的聲量雖高,但就「好評的比例」來講,其實E牌才是有較多正面評價的品牌,相對的A牌和C牌正負面評價大概參半,也就是這兩品牌相較其他比較品牌來說,評價的部份就是需要改進的地方了。
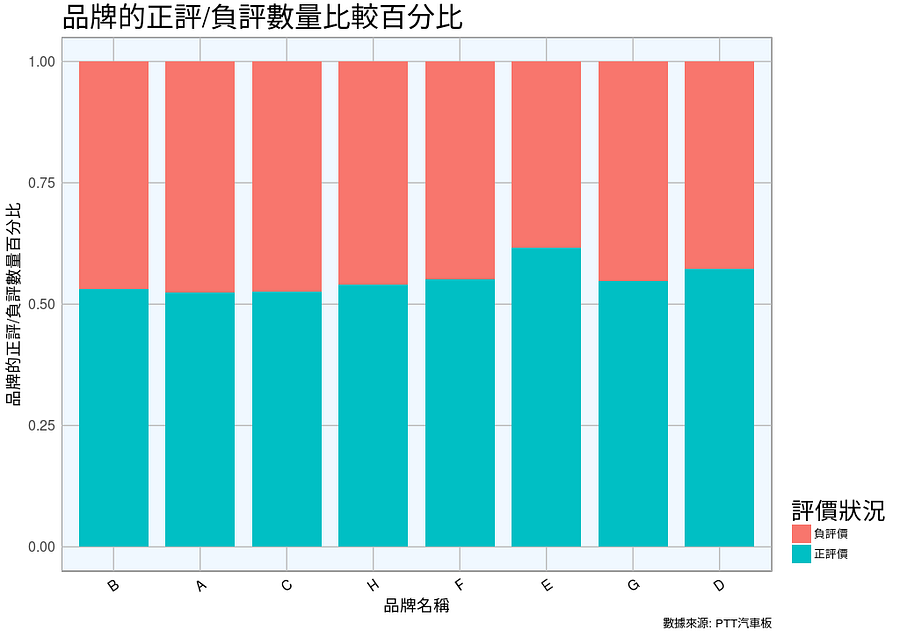
正負評對於企業來說是關重要,負評如潮的企業可能面臨倒閉,而有口皆碑的企業則有可能在網路的時代更如魚得水。
恩… 看起來都不錯了,但是有沒有更細部、更明確一點的呈現/視覺化方式?
定位圖
這時定位圖正式出場!定位圖得呈現均為「品牌相對比較的概念」。
讓我們實際來看看何謂定位圖「相對比較的概念」!
下圖Y軸為情感評價分析(網路好感度)百分比;X軸為網路聲量,將聲量與網路好感度做一個交叉分析,很明顯的可看出每個品牌目前被網友定位在什麼樣的地方,兩條虛線分別為網路聲量與網路好感度的總體平均值,劃分成四個象限:
- 第一象限:討論度高且好感度高,是網友心目中最理想的品牌,以兩軸平均值來看,發現此區並無一牌,顯示要達到理想品牌的各家汽車品牌還要更加油。
- 第二象限:討論度低但好感度高,是網友好感度上,稱頌的好品牌,不過聲量卻不比同業,例如D與E牌,好感度雖高,但是該兩品牌應該要多多努力加強網路上的討論度。
- 第三象限:討論度低且好感度低,是網友最不理想品牌,G、F、H品牌落在此區域,表示討論度與好感度要好好加強。
- 第四象限:網路聲量高,但是好感度低,是網友討論度高,但是負面爭議相較也較多,這些品牌有A、C、B,不過仔細觀看,這些品牌的好感度雖然小於第二象限的D與E牌,但正面評價都有>0.5,代表雖然相較他牌來說,A、C、B牌正評較差,但是還是高於負評! 所以可說A、C、B在聲量與好感度皆有不錯的成就,而應要加強的是他們可以聽聽顧客的需求,讓他們對這個品牌更加滿意,以讓這群年輕顧客好成為未來的主要顧客。
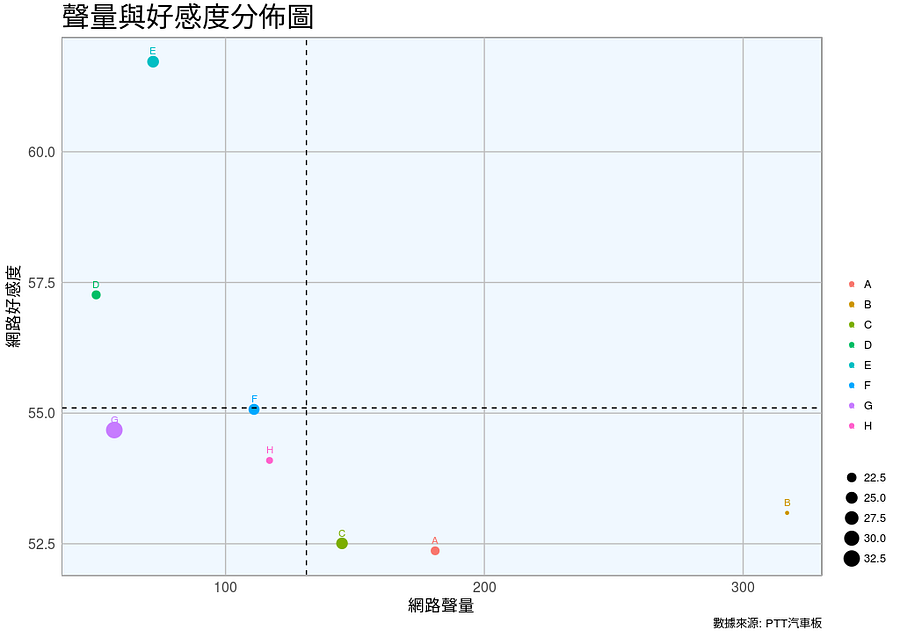
定位圖更容易將兩個變數交叉分析,變成人更容易看得懂的比較圖
雷達圖
雷達圖在視覺化中,可以多維度的方式展示各種品牌屬性,也因此,雷達圖在自然語言分析中,便是一非常好理解的「多維度定位圖」。而雷達圖上的特徵分數則是使用Glove深度學習模型評估產品與字詞之間的詞向量(權重),再使用Cosine Similarity找出與該產品與最相關的字詞距離,再以相關係數表明之,舉例來說:當提到行銷資料科學粉絲專頁,與該品牌最相關的字詞就有可能是「行銷」、「機器學習」等。
會使用Glove的方式來評估,便是因為我們要在大量的文本中僅可能考量到文字語意間的關係(Semantic meaning),讓僅可能不遺漏與該品牌相關的字詞。
還是不懂嗎? 讓我們以真正的實例來做給您看!
為了圖表的整潔度,圖中我們試著將兩象限的B、C、G三個品牌放入雷達圖中。這邊要請讀者特別注意,這個雷達圖並不代表產品真正的狀況,而是以網友對品牌認知的角度去看,因此假如您的品牌的訴求且號稱是最省油,但經過網友「嚴格」的評論下,卻可能不是這一回事,那您的品牌便可以依照消費者對品牌的認知,一方面進行調查,一方面在這方面下工夫。
回到下圖的實例分析,我們可以看出B和C牌的特徵分數幾乎是旗鼓相當的,但很明顯可以區分G的特徵分數較低,G在馬力、省油、扭力的部分,在消費者眼中,幾乎都沒有與該品牌相關,因此並沒有數值,那該品牌是不是可以在這幾個部分作升級或者包裝,以獲得更大的利益, 讓網友對這個品牌認知更完整。
雷達圖上的特徵也可以當汽車產業的「需求探勘」圖表喔!
另外,這張雷達圖也可以當汽車產業的「需求探勘」圖表,我們發現,在煞車上,僅有G牌明顯勝出,可見顧客對G的煞車情有獨鍾,如果B牌發現自己的消費者非常重視煞車功能,且對此一直有所輿論,B牌的下一個「潛在需求」便可能是「煞車性能」的改善,以滿足B牌顧客的需求,創造更多的商業利益。
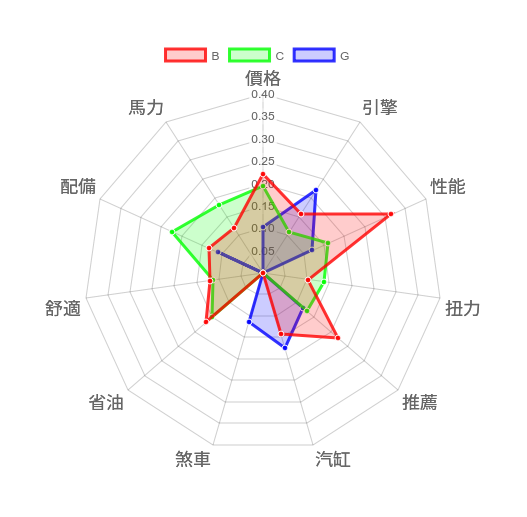
本雷達圖採用NLP深度學習Glove 模型,找出B、C、G在每一個字詞上的關聯性,關聯性越高,相關係數越高,代表該品牌常與該關鍵字詞論及相關
- 但是… 難道我們在定位中所看到的這些特徵變數(如:性能、扭力等),僅能使用專家知識來做判斷?
- 難道這些專家知識對營收一定會有影響嗎?
- 市場定位還有其他的面向?
敬請期待! 目標市場特徵選擇
所以在下一章節,我們會使用「機器學習」模型找出在「定位上」可以拿來使用的重要特徵變數,不但節省市場定位上專家或自己挑選特徵變數上的時間,而且挑選出來的特徵變數同樣對Y變數(營收、點擊率、銷售)有影響,如此,進行市場定位才真正能夠打中顧客核心,找出顧客真正care的特徵值,以精進與改善,增加更多企業利益。
當然,在市場定位的延伸上,我們會更深層一步探討定位圖對企業利益的影響,同時從龐雜的資料海中,找出為可能的需求處女地。
往後的文章都會持續在行銷資料科學粉絲專頁上發表喔!
再請大家多多follow我們的粉絲專頁:行銷資料科學
Enjoy Marketing Data Science!
作者:
鍾皓軒(臺灣行銷研究有限公司 共同創辦人)
楊超霆(臺灣行銷研究有限公司 資料科學研發工程師)
鍾皓軒(臺灣行銷研究有限公司 共同創辦人)
楊超霆(臺灣行銷研究有限公司 資料科學研發工程師)



留言
張貼留言