價值? 成本? 讓RFM模型輕輕鬆鬆評估一切!(附實現程式碼)
在RFM模型「系列 1」- 常貴客?新客? 讓RFM模型簡簡單單解釋一切!(附實現程式碼),我們利用了R與F的交叉分析,簡簡單單推導出不同客群的行銷方案。 並在假設條件下,該商場可以利用R與F的交叉分析,在一年多賺進168萬元的淨利。
而本次我們將專注在RFM模型中的消費金額(Monetary)分析,並回答系列1的三個問題:
- 有這麼多顧客區隔,更細部來說,這些區隔都值得我注意嗎? 難道一次客真的要放棄嗎?可以使用消費金額(Monetary)及成本評估顧客終生價值嗎?那該如何評估?
- 如何整合時間序列分析?難道時間序列沒有其他用途嗎?
在開始進行消費金額(Monetary)分析前,要請讀者先行了解四個概念:
- 商品毛利(Gross Margin, GM):每一件產品的毛利;簡單來說,就是「產品營收」- 「進貨的成本」。
- 顧客終身價值(Customer Lifetime Value, CLV):每一個顧客為我們貢獻的收入;簡單來說,就是對每個顧客購買的每一件商品進行「商品毛利」之加總。
- 顧客購買(取得)成本(Customer Acquisition Cost, CAC):為了要賣出商品,在每一個顧客上所花費的成本。
- 顧客獲利率(CLV/CAC Ratio):每一CAC可以為我們賺進多少的CLV。
哪些顧客區隔應該要放棄? 應該要保留?
有了上述概念後,接下來,讓我們來回答問題一:「有這麼多顧客區隔邊界,更細部來說,這些區隔都值得我注意嗎? 難道一次客真的要放棄嗎?可以使用消費金額(Monetary)及成本評估顧客終生價值嗎?那該如何評估?」
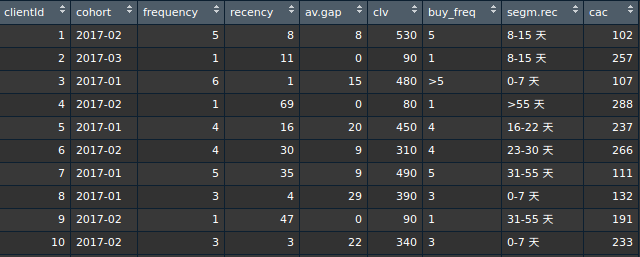
資料:
首先來看一下上一篇R與F交叉分析的資料格式:
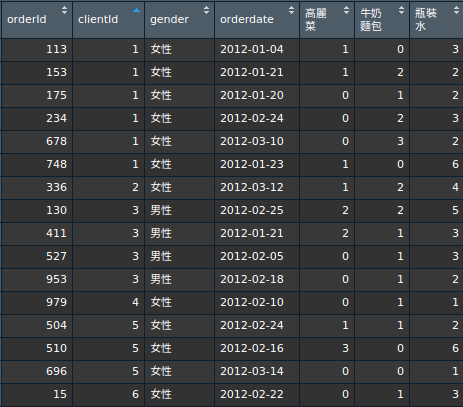
那我們再將CLV與CAC的資料加入考量,其中我們假定三樣商品的商品毛利:
- 瓶裝水 = 10
- 牛奶麵包 = 50
- 高麗菜 = 10
最終生成下述每個顧客CAC與CLV的資料。
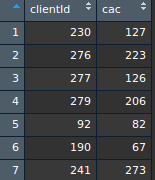
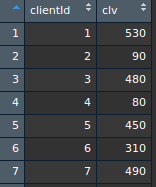
每個顧客的CAC與CLV資料結構
最後結合CLV與CAC的資料表就產生出來了!也就是在這張資料表中,除了可以進行R與F的交叉分析外,我們亦可開始進行「消費金額(Monetary)」的分析啦!
最後結合CLV與CAC的資料表就產生出來了!也就是在這張資料表中,除了可以進行R與F的交叉分析外,我們亦可開始進行「消費金額(Monetary)」的分析啦!
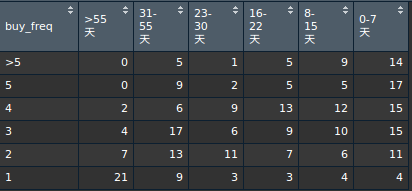
消費金額(Monetary)模型分析:
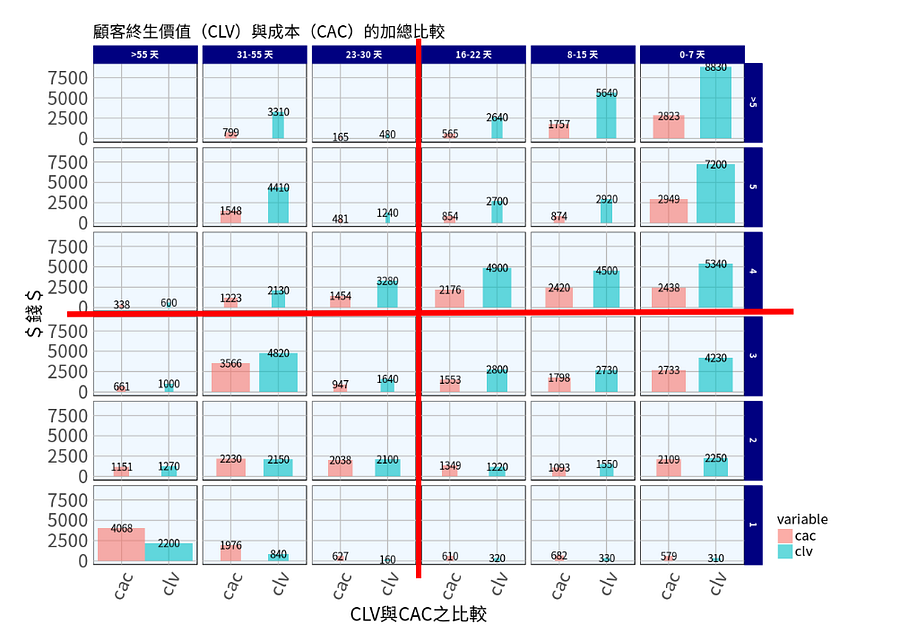
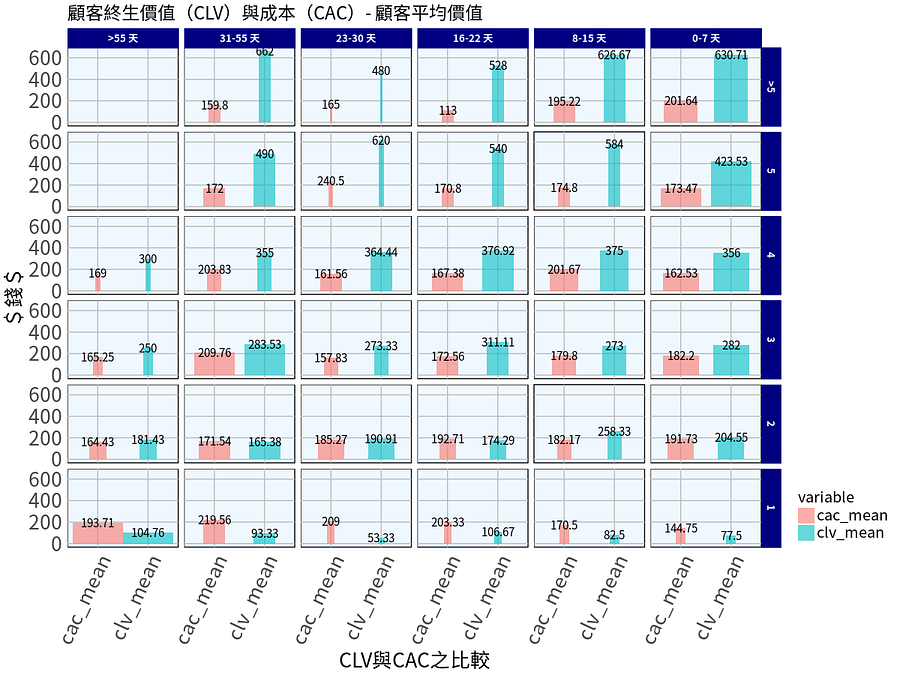
圖片X軸為CLV與CAC之比較,而Y軸對CLV來說則為營收金額的概念,對CAC來說則為成本的概念。藍色X軸則為R,藍色Y軸則為F。除此之外,我們還將「長條圖」的粗細以購買人數多寡表示之,越粗,代表越多人在此區隔購買,越細,則代表越少人在該區域購買。
有了顧客終生價值(CLV)與成本(CAC)的比較圖,讀者可以想想,如果你是行銷資料科學家或專業經理人,有了Monetary相關的資料,接著可能會做些甚麼?
首先,我們發現:
- 常貴客確實為最賺錢的區隔
- 新顧客隨著購買頻率的增加,CLV有逐漸上漲的趨勢
- 先前客部份則非常有趣,在31–55天內,消費達5次以上的顧客,人數多,且金額甚至高過16–22天內,消費達5次以上的顧客
- 一次客則發現成本花費高,且顧客消費效益不高…,但是人數似乎又是最多的區隔…
那… 所以哪些區隔要放棄?哪些要保留?
這時候,就需要使用到顧客獲利率(CLV/CAC Ratio)來做更直觀的計算,讓我們更清楚目前商場整體獲利狀況:
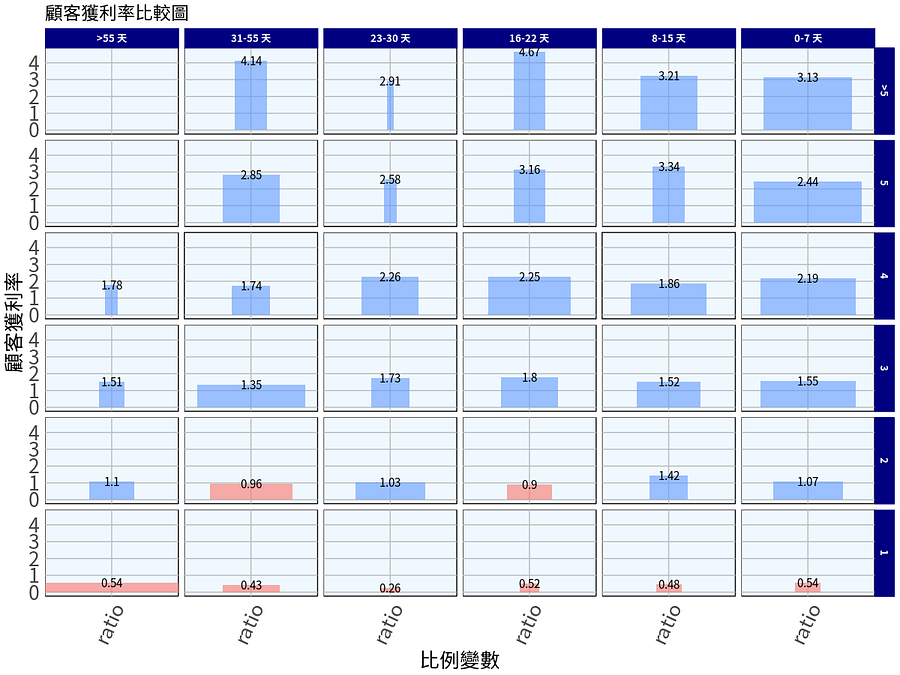
從顧客獲利率比較圖中,我們可以非常清楚了解幾個思考方向:
總體
我們可以看到紅色區隔均是投入1塊錢成本,反而無法回本的區隔,所以我們就可以考慮不在繼續投資。或者不在繼續投資「嗎」?
常貴客分析
- 在常貴客0–7天內消費5次以上的顧客中,我們每投入1塊錢的成本,就會賺得3.13元,這群人總共有14人,平均消費天數為3.93天,購買頻率為7.14,也就是一天平均消費1.82次,那一天就是 14* 1.82* (3.13–1) = 54.2元的淨收。
- 在常貴客16–22天內消費5次以上的顧客中,我們每投入1塊錢的成本,就會賺得4.67元,這群人總共有5人,平均消費天數為18.4天,購買頻率為6.4,也就是一天平均消費0.35次,那一天就是 5 * 0.35 * (3.67–1) =4.67元的淨收。
- 在常貴客0–7天內消費5次的顧客中,我們每投入1塊錢的成本,就會賺得2.44元,這群人總共有17人,平均消費天數為3.82天,購買頻率為5,也就是一天平均消費0.77次,那一天就是 17* 0.77* (2.44–1) = 18.72元的淨收。
如果不考量該商場的其他布局策略,純粹以數字來評斷,讀者有沒有看出些什麼?
在常貴客的第1點與第3點比較可發現,第1點的人數明顯不足,如果能利用行銷活動將第3點的5個人轉換到第1點,如果根據過往經驗,將成本變高提高18%,花1.15元能一樣能賺得3.13元,且能夠吸引5個人,我們將可以一天多賺7.55元。
原樣:14* 1.82* (3.13–1) +17* 0.77* (2.44–1) = 73.12 轉換後=(14+5)人* 1.82* (3.13–1.18) + (17-5)人* 0.77* (2.44-1) = 80.67
如果我們將人數「簡單」的放大10倍:
原樣:140* 1.82* (3.13-1) + 170 * 0.77* (2.44–1) =731.22 轉換後=(140+50)人* 1.82* (3.13–1.5) + (170-50)人* 0.77* (2.44-1) = 806.69
這樣一天就多賺了75.47元,一個月就是2264元。
哇! 算出來了! 好棒棒!
但… 恩…有這樣簡單「嗎」?
這時候讀者心中一定激起了一個至關重要的疑問:「這看起來就是一個時間的綜整結果,能不能給我一個細部的趨勢變化圖? 更有利於我做行銷資源非配,而非一概而論?」


世界上最遙遠的距離,就是「從消費者的口袋到我的口袋」,但是談到RFM模型「消費金額(Monetary)」簡單明瞭的分析方法,讓消費者與我的距離越來越親近,於是我們又不由自主開心的笑了起來!
如何整合時間序列分析?
這時候就要綜整第一與第二個問題:「將消費金額(Monetary)以時間序列的方式進行趨勢整合,看出不同顧客區隔的趨勢分析,了解在每一個顧客區隔再投入資源不便的狀況下,哪一個區隔在未來是有發展性的 」。
要進行時間序列的消費金額分析,我們可將顧客的第一次購買日期當作基準,統計在這往後,該顧客的購買頻率(F)、最近一次消費天數(R)、CAC與CLV的總平均,如此我便能知道:
- 每個月份消費者的購買軌跡;例如:cliendId 1 的消費者自從2017–02就有消費紀錄,而最近有5次消費、最近一次購買是則是8天前。如此便知在2017–02時至今日,他依舊是我的常貴客。
- 我們還能知道每個顧客區隔中,到底是那一個月份進來購買的顧客會是我們最值得投資的目標對象。
- 再來就是,哪幾顧客區隔我們應該可以考量繼續或放棄投入資源。
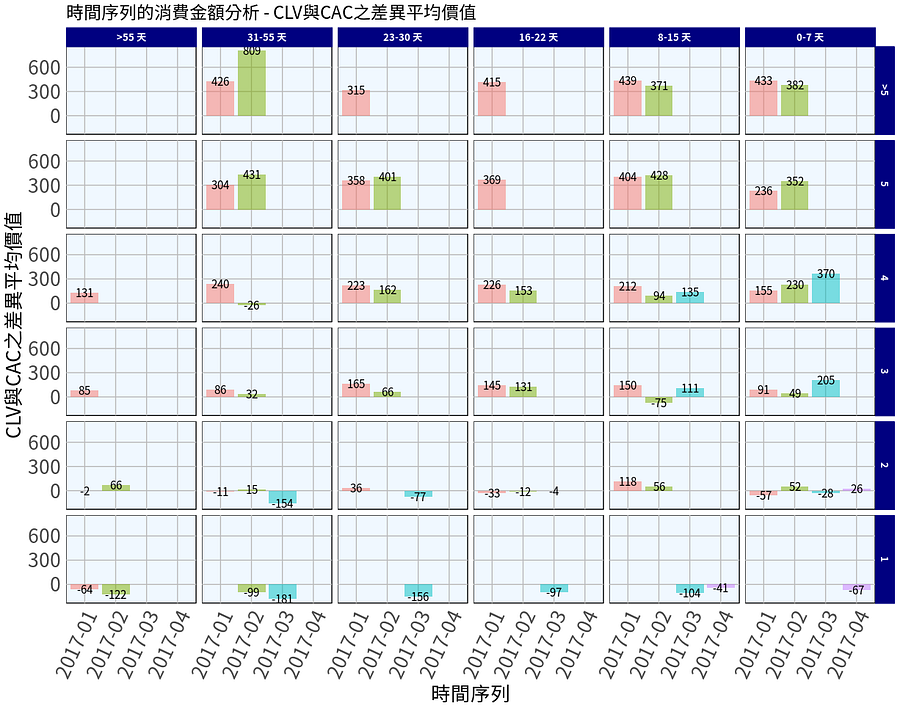
我們假設報告的時間點先以為2017–04–11為基底,將時間序列的消費金額分析製作出來後,我們可以很清楚看到,在本月的營收:
- 最近一次購買天數0–7天且購買頻率4次的常貴客的數字從2017–01的155元平均顧客淨利一直到2017–03的370平均顧客淨利,有持續增長的趨勢存在,且該區隔的逐月新進顧客增長許多,建議可以將較多的資源比重依照月份淨值多寡進行行銷資源分配。
- 再來看看最近一次購買天數0–7天且購買頻率2次的潛在客,很清楚發現,我們可以將有限的行銷資源投放到2017–02與2017–04該區隔新進顧客,排除2017–01及2017–03的顧客。就算要重新喚這群淨值為負的顧客,也可以將淨值-28的2017–03的顧客當作資源投放的優先考量。所以並非顧客獲利率大於1以上,我們就一定要將所有資源投入到整體顧客區隔,而是可以根據月份等商場注重的變數做「區隔再區隔」,精準鎖定行銷資源的投放標的。
- 再來看一個例子,我們再看到最近一次購買天數31–55天且購買頻率2次的一次客,在四月份時,有2017–02進來消費的這群一次客產生15元的淨值,然而這一顧客區隔以總體來說,他的總顧客獲利率竟然是0.96,雖然2017–02這群一次客貢獻淨值很低,但是相對有機會將他們拉抬上來,成為潛在顧客。
- 再看最近一次購買天數16–22天且購買頻率2次的潛在顧客,雖然總顧客獲利率是0.9,但是其逐月新進顧客貢獻的淨值接有所改善,如果商場放棄掉他們,是不是又可惜了些?
所以我們從單點的顧客獲利率圖到時間序列的消費金額分析圖中,給我們的insight便是可以依照時間點的不同而妥當的去分配自己的行銷資源,而非總顧客獲利率<1就全盤放棄考量,那除了時間外,我可不可以在依照其他變數進行「區隔再區隔」? 當然可以!時間序列可被替換成「品牌、品質、滿意程度等對商品利益有所影響的變數,精緻化行銷資源」,由此可知,商場必須要將顧客區分得更細緻,方能妥善運用行銷資源,將行銷利益最大化!
敬請期待!RFM在行銷活動(campaign)之評估
下一篇文章,我們會針對下述兩問題細細解讀給讀者:
- 我會對各種不同區隔的顧客進行行銷活動,這些行銷活動該如何評估? 成效該怎樣計算?
- 如果我搭配預測模型的來預測顧客未來的價值,該如何圖像化?
往後的文章都會持續在行銷資料科學粉絲專頁上發表喔!
再請大家多多follow我們的粉絲專頁:行銷資料科學
Enjoy Marketing Data Science!
作者:
鍾皓軒(臺灣行銷研究有限公司 共同創辦人)
鍾皓軒(臺灣行銷研究有限公司 共同創辦人)


留言
張貼留言